TalkPlayData 2
- 📄 Paper: On arXiv: "TalkPlayData 2: An Agentic Synthetic Data Pipeline for Multimodal Conversational Music Recommendation"
- 📊 Dataset: Hugging Face. 16,500 conversations in total. 15,500 in training split and 1,000 in test split.
- 💻 Generation Code: GitHub — self-contained and runnable with a small dummy set, designed to expose the exact prompts and the end-to-end process.
What is TalkPlayData 2?
We generate realistic conversation data for music recommendation research that covers various conversation scenarios and involves multimodal aspects of music.
We achieve it by letting two LLMs talk to each other about music, since LLMs can definitely talk to each other coherently and naturally. But we need grounding music data to make the conversation realistic and relevant to real music items we have. So, we use a listening session dataset to condition the conversation, where each session's tracks become the recommendation pool of the resulting conversation.
But that's not enough. We also condition the Listener LLM with a conversation goal, which is finetuned based on the recommendation pool, by the Goal LLM. And - to do it better, we also condition the Listener LLM with a Listener Profile, which is based on basic demography and inferred information of the listener.
Information Imbalance is an important aspect of TalkPlayData 2. This Listener Profile is shared with the Goal LLM, Listener LLM, and the Recsys LLM. However, the conversation goal is shared only with the Listener LLM, which queries and responds to the Recsys LLM to achieve the goal. The Recsys LLM doesn't know the goal, but it knows the recommendation pool and recommends music each turn based on the Listener LLM's messages.
As a result, this is essentially an agentic pipeline, simulating real-world conversations between a listener and a music recommender.
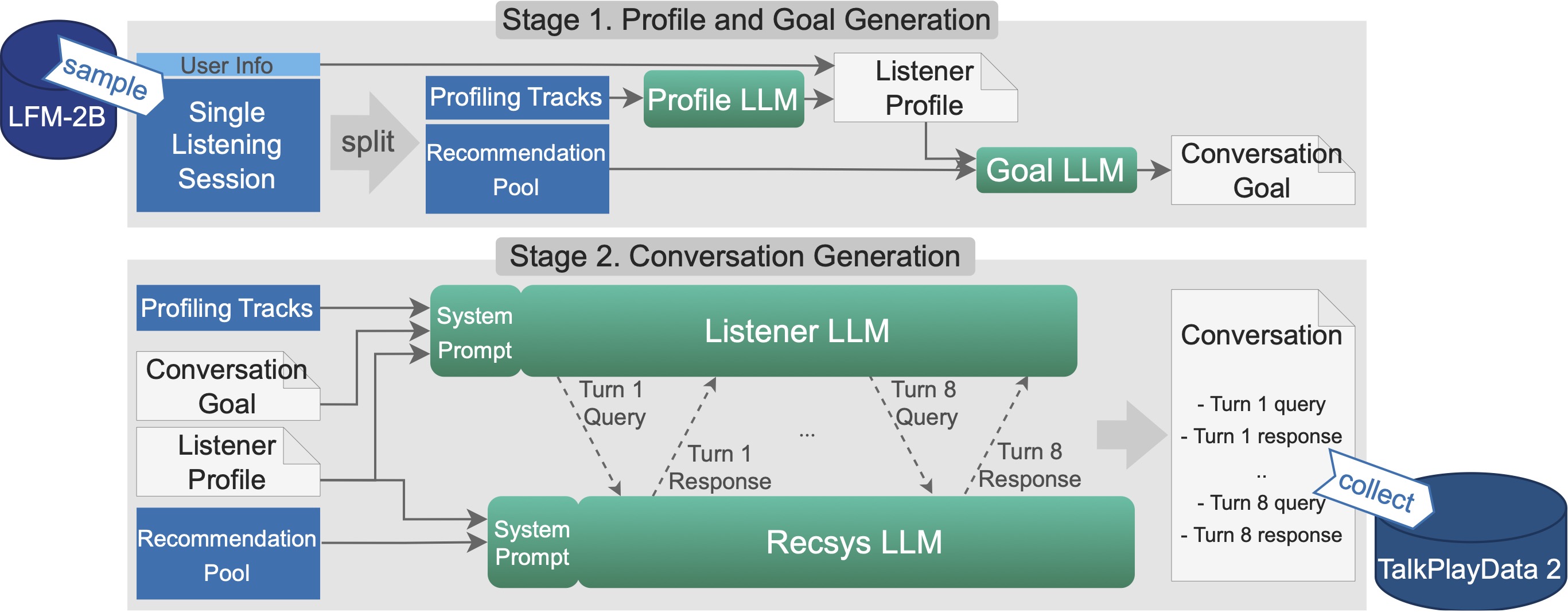
Pipeline for generating conversational music recommendation data
Multimodal and Conversational, in one LLM.
In our pipeline, all the LLMs are multimodal - they can listen to the audio and see images, besides understanding various sub-modalities in text such as lyrics and chords.
Not to mention they're conversational - just like TalkPlay 1, that's why we're using LLMs as a recommendation engine.
This is nicely put along the line of bigger models, and less number of components -- extending the scope of a single model (LLM). An important contrast to the existing systems which have different, separate components to handle different modalities, connected non-differentially.
So, what can you do with TalkPlayData 2?
We have released the code - you can inspect the generation process in detail.
You can also use our dataset train and evaluate your conversational music recommender.
Since the data even includes the listener's evaluation on each recommendation, you can even finetune / apply RL to the recommender and optimize the recommendation performance.